
Streamlining investment decision making
Read more >
Learn about Logic from Probability Processing (LPP) which ensures precise, reliable AI outputs and overcomes traditional challenges of data safety and accuracy typically associated with LLMs.

What is the number one problem for companies looking to embrace the potential of Large Language Models (LLM’s) for their businesses? The answer is another question: How are you supposed to implement a technology whose responses are, at best, hitting the mark only 70% of the time? So there is the challenge. Nearly every C-Suite executive has spent time trying to harness LLM’s for their businesses, yet few have successfully accomplished the task despite at least a year of access to this brand of AI technology. Our message: We’ve been using LLM’s the wrong way…
At Ragu, we meet all kinds of clients, some who have very specific ideas of what they want to achieve, and others who need guidance adapting LLM’s for their businesses. All have the same concerns about how much they can trust pushing “LLM magic” into mission critical functions. They worry about the safety of their data and IP, and they fear any implementation could fail as spectacularly as Air Canada’s chatbot, which made up its own policy and started offering full refunds for bereavement fares.
The C-Suite’s concerns about LLMs are valid. Firstly, improper LLM usage can jeopardize data safety and expose valuable intellectual property. Secondly, it’s difficult to guardrail LLMs from “hallucinating” or generating inaccurate and potentially harmful outputs. Lastly, an LLM is only as good as the “crowd wisdom” from which it was trained. It is never going to be able to consider the outlier thinking that you might desire because its inherent logic comes from the vast reckoning of logic derived from the probability of word sets that appear most often together. Word sets in the outlier thinking you might require, are necessarily lower on the probability curve, and therefore not found in an LLM’s responses.

So, how can we harness the immense potential of Large Language Models (LLMs)? The answer lies in challenging our current paradigm and rethinking how we approach these powerful tools. The traditional notion of simply asking an LLM to perform a task and expecting flawless results is misguided. If you’re building your strategy around this idea, it’s time to take a step back and reconsider.
LLMs aren’t inherently designed to execute complex tasks on command. Instead, their true strength lies in their ability to understand and process human logic. They can grasp the nuances of our intentions, deciphering the underlying reasoning behind our queries, and respond with middle of the bell curve responses from their crowd wisdom.
At Ragu, we’ve pioneered Logic from Probability Processing (LPP), a groundbreaking approach that harnesses LLMs’ ability to deliver logical responses to inputs based on their inherent understanding of the probability for word associations. LPP is a new paradigm for using Large Language Models that focuses on harnessing their ability to understand and respond to human logic, rather than expecting them to perform complex tasks with a single prompt. LPP recognizes that LLMs excel at providing responses based on the most probable word sets, making them ideal for processing simple, verifiable tasks within the middle of the probability curve.
At a high level, an LPP system consists of three key components: a Retrieve and Generate (RAG) system, Agents for sequential task processing, and LLMs. The RAG system serves as a source of truth and knowledge, ensuring accuracy and consistency in the LLM’s responses. Agents break down complex problems into smaller, manageable tasks, allowing the LLM to process them in a structured sequence. By combining these elements, LPP systems become immensely powerful, enabling businesses to leverage the full potential of LLMs while minimizing the risks associated with traditional LLM usage.
To explain the difference between LLM and LPP, think of traditional LLM usage as trying to bake a cake by dumping all the ingredients into a bowl (the “prompt”) and expecting a perfect result. In contrast, LPP is like following a recipe step-by-step, measuring each ingredient carefully, and verifying the consistency at each stage before moving on to the next. Just as a well-executed recipe leads to a delicious cake, LPP breaks down complex problems into smaller, manageable tasks, ensuring accuracy and reliability at every step. This approach allows businesses to leverage the power of LLMs while minimizing the risks associated with “hallucinations” or inconsistent results. By shifting from the “magic wand” mentality of traditional LLM usage to the more structured and verifiable approach of LPP, businesses can unlock the true potential of these powerful tools and achieve better outcomes with greater confidence.
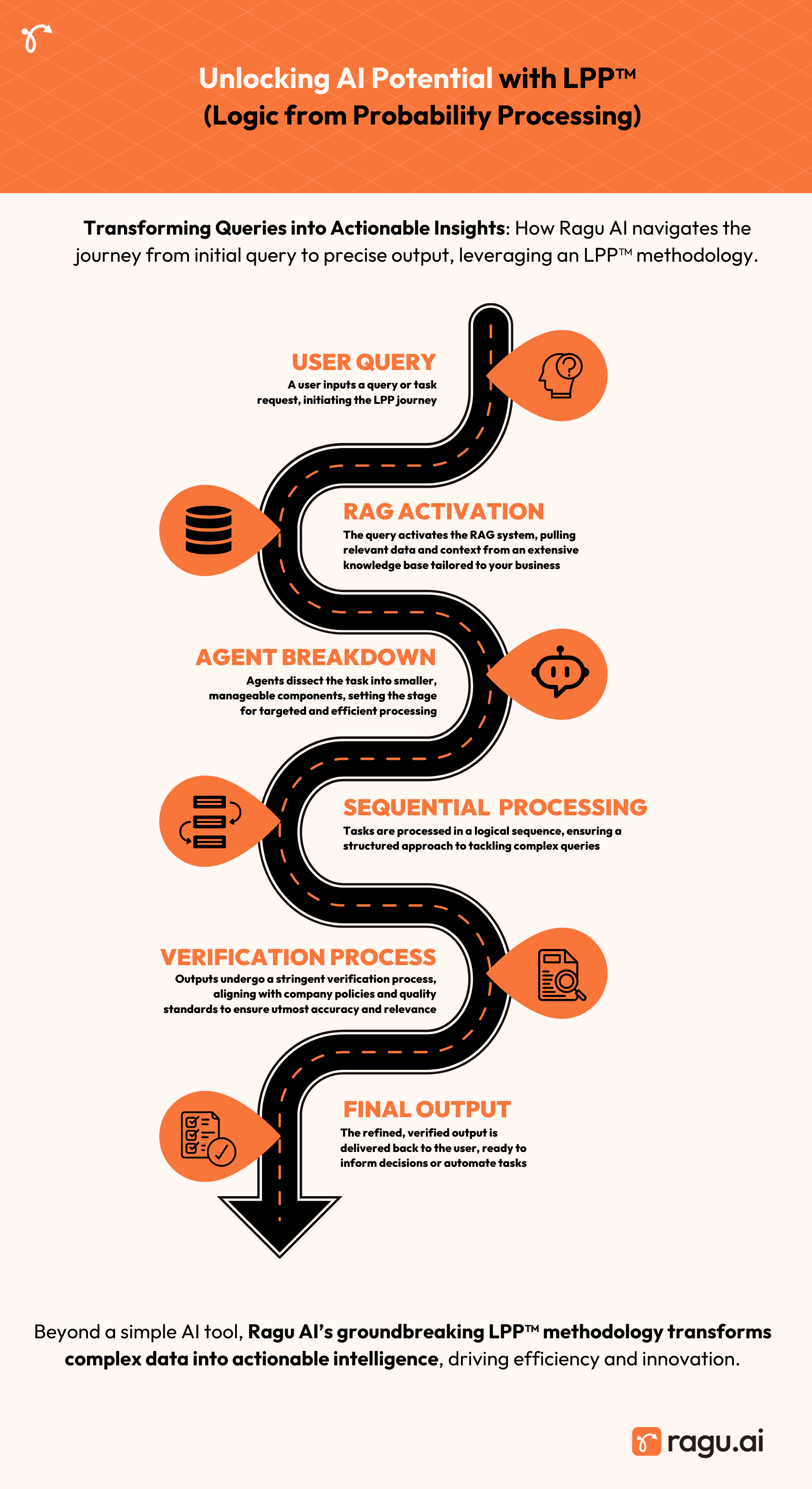
So how do you take advantage of LPP? To start, recognize that an LLM is only one part of your AI stack, you actually need: RAG (also referred to as “Retrieval Augmented Generation”) + LLM + Agents & Prompt Architecture + Verification Layer. Let me explain what each of these components does and why they are necessary:
A Retrieve and Generate (RAG) system acts as a comprehensive knowledge base for an LLM, augmenting its pre-existing “crowd wisdom” with company-specific intellectual property (IP) and expertise. By integrating a RAG system, businesses can ensure that their LLMs are informed by a single, reliable source of truth, aligning the AI’s responses with the company’s unique knowledge and best practices. This approach not only enhances the accuracy and relevance of the LLM’s outputs but also significantly reduces the risk of “hallucinations” or inconsistent results that may arise from relying solely on the LLM’s general training data. Think of a RAG system as a powerful, custom-tailored “hard drive” that stores and supplies all the essential corporate knowledge your AI (LLM) needs to deliver accurate, context-specific insights and solutions. With a RAG system in place, your LLM becomes an extension of your organization’s collective intelligence, empowering it to make informed decisions and generate valuable outputs that align with your company’s goals and values.

Why simple? Consider asking an LLM to produce a business plan – if you try this at home you’ll find you get a little over a single page of output from any LLM, and it will sound like an advertisement for your idea with very little substance. If instead you ask an LLM to draft 25 questions you should answer about your business model in your business plan, the LLM will provide a set of highly relevant and thought-provoking inquiries. If you then ask the LLM to answer all 25 questions one at a time, you’ll get pretty decent answers. If you then deposit those questions and answers into your RAG system and then ask the LLM to create an outline for your business plan, it will, again, do a good job. With your RAG system now enriched with the 25 key questions, their corresponding answers, the plan outline, and any other pertinent company information, you can leverage the full potential of your LLM to create a comprehensive and well-crafted business plan. By tasking the LLM to focus on one outline point at a time, you enable it to generate detailed, insightful content that is informed by the wealth of knowledge stored in your RAG system. This iterative process allows the LLM to gradually construct a robust, coherent, and highly relevant draft of your business plan, with each section building upon the information and context provided by the previous steps.

The business plan example mentioned above demonstrates the use of multiple agents working together in a sequence to achieve a desired outcome. Each of these tasks can be considered an “Agent” in LLM terminology, with a specific goal contributing to the overall objective. In a real-world scenario, creating a comprehensive business plan would likely involve deploying a much larger number of agents, perhaps five times as many as in the given example. However, the success of an LPP system relies not only on the number of agents but also on the careful design and consideration of each agent’s “ask” or prompt. Two crucial aspects should be taken into account when formulating an agent’s prompt. Firstly, the request should be simple and straightforward, ensuring that the expected output falls well within the middle of the probability curve of responses. In other words, the agent’s response should be predictable and aligned with the “crowd wisdom” derived from the RAG data sets provided. This approach minimizes the risk of unexpected or irrelevant outputs that could derail the process.

Secondly, the sequence of agents must be architected in a logical manner, with each agent building upon the work of its predecessor and setting the stage for the next agent in line. The output of one agent should seamlessly feed into the input of the next, creating a coherent and purposeful progression towards the desired outcome. It is crucial to ensure that the sequence of tasks (e.g., task A, followed by task B, then task C) has a high probability of generating the intended result. This requires careful planning, processing, and testing to refine the LPP system’s architecture.
The importance of verification agents in an LPP system cannot be overstated. These agents serve as critical checkpoints, ensuring that the outputs generated by other agents align with company policies, guidelines, and objectives. Let’s consider the example of Air Canada’s chatbot mishap. If the company had implemented a verification agent to review the chatbot’s responses before they were delivered to customers, the issue could have been prevented. The verification agent would have cross-checked the chatbot’s proposed action of granting refunds against Air Canada’s refund policy, identifying the discrepancy and preventing the erroneous response from being sent. In a well-designed LPP system, each agent or task is followed by a verification step before proceeding to the next stage. This architecture creates a series of safeguards that maintain the integrity and accuracy of the system’s outputs. By incorporating verification agents throughout the process, businesses can minimize the risk of errors, inconsistencies, or actions that deviate from company policies. These agents act as vigilant guardians, ensuring that the LLM’s responses are not only technically correct but also aligned with the company’s values, guidelines, and objectives.

OK, this layer is optional today, but it won’t be tomorrow (it’s part of the reason that the folks at Groq should be so excited). In the business plan builder example above, there are likely no less than 500 tasks that need to be executed for a successful result, perhaps 5,000… But imagine if your company needed to process 5 million tasks to develop a new CPG product for market? All of a sudden, speed of response becomes critical, you can’t wait 30 seconds for each of 5 million steps. You need to process at computer speeds. Again, the fact that Groq is processing LLM responses in the millisecond range effectively opens up this type of Logic from Probability Processor to become a new kind of Operating System. A new kind of supercomputer.
For most of our clients today, this is not required… but that’s only due to the limitations of imagination. We are already thinking on a scale that makes us expect @Jonathon and @Chamath will answer our phone calls in the not too distant future.
So, what does all of this mean for businesses seeking to harness the power of LLMs? It means that if you’re encountering challenges in deploying these technologies effectively, you’re not alone. Many organizations have discovered that extracting magic from LLMs requires more than just crafting the right prompts. To truly unlock their potential, we need to approach LLMs with a strategic mindset, understanding their strengths and limitations. At Ragu.AI, we have made it our mission to help businesses navigate this complex landscape. Our team of experts has spent countless hours researching, testing, and refining the best practices for implementing LLMs in real-world scenarios. We understand that success lies in asking the right questions, in the right way, and ensuring that the queries fall within the LLM’s optimal response range. We recognize the importance of integrating RAG-based knowledge sets, incorporating validation layers, and architecting a robust system of requests and answers.

While implementing LLMs successfully may seem daunting, we are here to simplify the process for you. Our solutions leverage the Logic from Probability Processing (LPP) approach, enabling businesses to harness the power of LLMs with confidence. We have already achieved remarkable results for our clients, and we are continuously working to optimize and enhance our offerings.
At Ragu.AI, we are committed to being your trusted partner in the world of LLMs. Our solutions are designed to empower your business, streamline your processes, and unlock unprecedented productivity gains. If you’re ready to take your organization to the next level with cutting-edge AI technologies, we invite you to join us on this exciting journey. Together, we can redefine what’s possible
Ready to unlock the full potential of LLMs tailored to your business? Contact Ragu.AI today for a game-changing consultation.
Learn how brands and companies are implementing AI and RAG to transform the way they work.
RAG represents a significant advancement in AI capabilities. Unlike traditional AI models relying solely on pre-trained knowledge, RAG combines large language models with real-time information retrieval.

Streamlining global human resources with a tailored, AI-powered solution.